
Scripts, applications, and CI/CD pipelines all require secrets to operate. These secrets include API keys, tokens, passwords, certificates, private keys or similar sensitive pieces of information. Unfortunately, these secrets may lead to data breaches affecting you and your organisation if the secrets end up in your source code.
This article explains how to keep your software repositories free of passwords, tokens, and private keys.
How code leaks increase security risks?
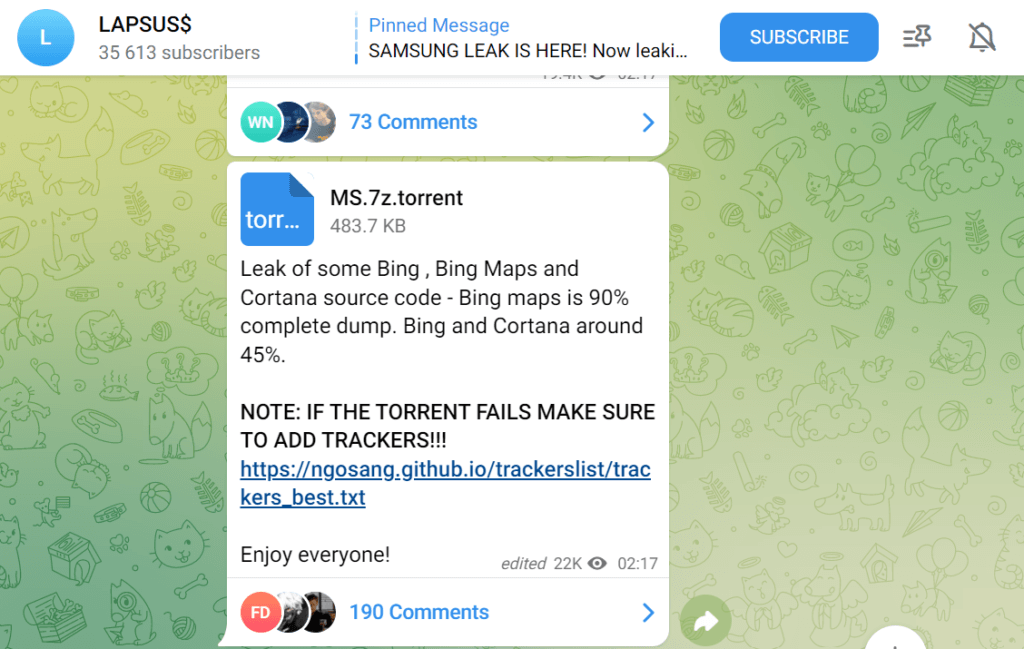
A recent source code leak affecting Samsung made numerous SSH private keys, GitHub Enterprise API tokens, Google Oauth2 tokens, AWS IAM credentials, and company email sign-in details public. The involuntary leak was published on the internet by The Lapsus$ hacking group. What a source code like this can do are the followings:
- Cloud API keys (e.g. Azure, AWS, Google Cloud) can be used to get a foothold into your infrastructure. Attackers can open network ports, launch virtual machines to mine cryptocurrency or reset administrator passwords to get access to your VMs.
- SSH private keys can be abused to sign in to any internet-facing servers.
- Email credentials can be used in Business Email Compromise (BEC) scams.
On the one hand, when source code spills onto the internet, the potential damage is somewhat limited. For an adversary to exploit this situation, they need to analyse the leak for critical bugs like remote code execution vulnerabilities. Although critical bugs would allow an adversary to launch successful attacks against your organisation, the chances of an adversary taking this path are low.
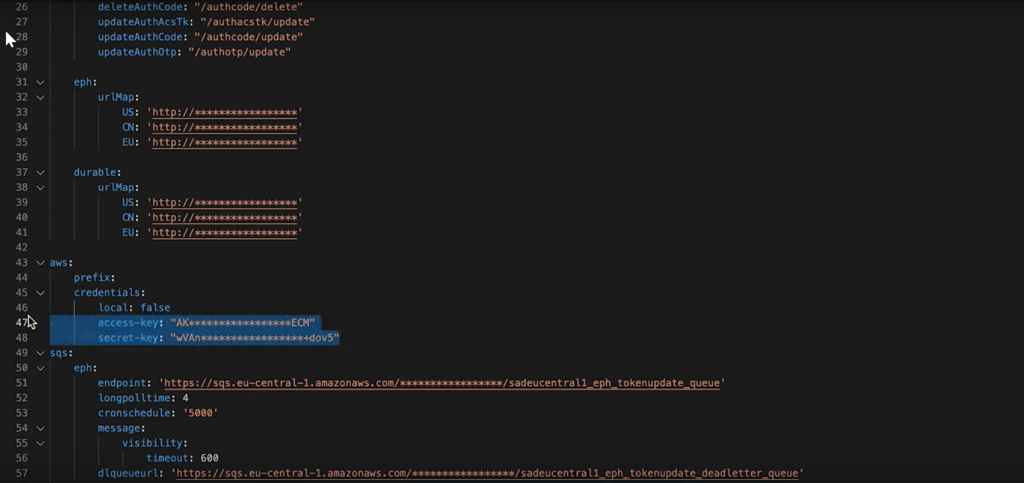
On the other hand, if the leaked source code features tokens, keys and passwords, the damage potential is more extensive. In other words, if secrets are kept in the source code (e.g. AWS API keys, SSH keys), the adversary may be able to gain instant access to your IT environment by abusing those secrets.
How can source code leak to the internet?
There are different possible ways how your private source code repositories could start circulating on the public internet. For instance:
- The software repository is set to public by accident; or
- A developer’s laptop is lost and found by an adversary; or
- A developer’s workstation gets compromised by malware.
Accidental publication
We need not go far for examples of public repos going public. In 2018, the Australian company Onehalf left a large volume of medical information of hundreds of individuals and internal HR data publicly available for everyone to see. Another classic example is Uber, when developers left usernames and passwords available in the company’s GitHub repositories. What are the potential consequences of a leak like this? According to independent research, it takes about 34 minutes for a leaked credential on GitHub to be abused by someone on the internet.
Malware and hacking
As for the malware compromise scenario, The Lapsus$ hacking group stole 200 GB of source code from Samsung and Nvidia and made publicly available on the internet. Lapsus$ members also leaked source code from Apple, Facebook, DHL, Microsoft, Ubisoft, and Vodafone — all in 2022! These attacks are common because Lapsus$ compromised the workstations with a combination of classic phishing emails and malware code.
Code and secret sprawl
Another scenario of the source code leaks is when software repositories are shared amongst internal teams or third parties as the application evolves. As an application is getting more complex, more and more entities need access to the source code. These include Q&A teams, external contractors and freelancers, CI/CD pipelines, backup procedures, and the list goes on. Therefore, the more your software repositories are shared across your organisation, the higher the chances of the source code getting into the wrong hands.
It is probably a cliché that the attackers usually choose the path of the least resistance. Therefore, if your source code hygiene is the weakest link in your SDLC, the adversaries will go after those sweet-sweet secrets kept in your code. For example, your version control system may be locked down with two-factor authentication, strict firewall rules, micro-segmentation, detailed logging, etc. But these are all ineffective if one of your external contractors stores a clone of your software repository on GitHub with 2FA not enabled.
Cyber risks in the supply chain
Last but not least, even if you do everything right, third-party systems can still get compromised. For instance, Salesforce was caught off-guard when their private repositories were leaked onto the internet thanks to the recent Heroku data breach. The Salesforce breach can be classified as a classic case of supply chain attack. Last year, the European Union Information Security Agency (ENISA) paper reported a four-time increase in supply chain attacks in 2021 compared to the previous period. So, not surprisingly, one cornerstone area of the Australian Information Security Manual (ISM) is the management of supply chain risks.
Source code finds its way
To sum it up, software developers have less and less control over your source code in modern environments. The potential consequence of a source code leak is minor when sensitive data is not kept in code. As this makes the attack surface smaller, code auditing exercises looking for sensitive data are more relevant than ever.
The following section looks at the various practices of keeping your software repositories free of unwanted secrets.
Maintaining source code hygiene
Your source code can be sanitised from any sensitive data with an all-inclusive approach. To keep everything simple, we divided our recommendations by the classic people, process, and technology (PPT) dimensions (aka. the Golden Triangle).
Relying on people across your organisation
As for people, the first line of defence should be your developers writing source code. Education and training can raise attention amongst your developers to not add any sensitive data to the source code in the first place. Furthermore, we recommend identifying other channels where your source code may be scrutinised. This person could be a fellow developer who happens to be reviewing the pull request on GitHub, a Q&A team member running code tests or a system administrator who deploys the latest updates to the production environment.

Not just developers but also people managing or consuming the source code should receive security awareness training. As the Onehalf data breach demonstrates, software repos could end up in the open because someone is not aware of the appropriate settings of your version control platform. Therefore, train all relevant people to securely store, transfer and manage source code.
Code review processes in your SDLC
The second approach to a good source code regime is putting the right processes in place. For instance, source code reviews should be an integral part of your software development lifecycle (SDLC).
First, we recommend mandating that changes should go through a peer-review process. In modern version control systems, this manifests as pull request reviews. Apart from bugs and code styling issues, the reviewers should look for sensitive data in the proposed code change before anything is committed back to the main branch.
Also, you may want to involve other entities to help you maintain code health in your organisation. For example, third-party security firms can not only do risk assessments and penetration tests, but they can also audit source code. Your senior developers or the internal security team could help with the code reviews for a more budget-friendly approach. However, an independent reviewer with a strong security mindset could flag problems in your codebase that your internal teams may not recognise as high-risk issues.
Furthermore, consider putting checklists in place and use them before any significant change is pushed into production. For example, a checklist could require your Q&A team to review all recent code changes for unwanted secrets.
Code auditing procedures should be an integral part of your SDLC. First, identify all relevant stakeholders and develop their competency for code audits. Then put the processes in place requiring them to audit your codebase at certain checkpoints.
Scaling up with technology
The last piece of the puzzle is technology. As everyone already knows, engineering hours are costly, so manual code reviews can be time-consuming. Also, the quality and, therefore, the outcome of the code review is unpredictable, according to research. This is where automation and a wide range of security tools can help. They not only require fewer human resources to operate but can provide a more predictable quality of code audit reports.
We have several options available for automated source code analysis on the open-source front. A popular choice for secret scanning is TruffleHog, which just released the v3 branch with many powerful features. Other automated open-source applications include gitleaks, git-secrets, talisman and repo-security-scanner. Big tech companies like Yelp publishes detect-secrets, and Auth0 develops repo-supervisor for secret scanning.

On the other hand, commercial apps can offer convenience features like easy integration with GitHub and Bitbucket or eye-candy like colourful dashboards and reports. Paid code scanning services include GitGuardian, Spectral, Shiftleft and GitHub Advanced Security. Cloud-native tools include AWS CodeGuru, but this service only supports Java and Python programming languages.
For a more comprehensive list of open-source and paid services, please refer to the fantastic collection at OWASP and NIST.
To get the most out of these solutions, they should be an integral part of your SDLC in multiple ways.
- First, the code scanning tools should be used as part of your code quality assurance procedure. If you have gates in your project lifecycle, we recommend code scanning before the project moves on to the next phase.
- Second, code scanning tools can be integrated into your CI/CD pipelines. For example, GitHub Actions can scan any additions to the software repository almost instantaneously. Azure DevOps, AWS CodeBuild, or Jenkins pipelines can also run these tools as an additional step of the build process.
- Last, commercial tools can integrate into your source version control platforms. They usually support GitHub, GitHub Enterprise and Bitbucket. The obvious benefit of the commercial choice is the low overhead of the initial setup.
Scrubbing secrets from the source code
What needs to happen once the people, processes and technology are in place and a secret is flagged? Because of the nature of Git and similar version control systems, it is not enough to remove sensitive data from the latest commit. Unfortunately, the commit history will still feature the sensitive data for everyone to see. Also, because of the code sprawl, you cannot ensure that the secret is not compromised already or will in the future.
Therefore, we recommend the following three actions to scrub sensitive data:
- Remove the offending secret (password, token, etc.) from the source code; and
- From the commit history; and finally
- Rotate the secret.
To scrub any unwanted data from the repository and its commit history, you need to rewrite the Git history with purpose-built tools like BFG Repo-Cleaner, git filter-repo or git-secret-remove. Once the repo is scrubbed locally, it needs to be force-pushed back to GitHub or Bitbucket to remove secrets for good. These tools should address step 1. and step 2. Because of the distributed nature of Git, the secret may be kept elsewhere. Therefore, #3. is a critical step not to be left out of your code scrubbing process.
Conclusion
Recent security breaches demonstrate that secrets should not be kept in the source code. Furthermore, recent incidents illustrate that secrets can allow adversaries to access and compromise production systems and data. Therefore, people, processes, and technology should work together in your organisation to keep the software repositories free of unwanted sensitive data. The codebase can be kept free of secrets with trained and well-educated staff, formal code review processes and audit checklists, purpose-built tools and automation, and code scrubbing processes.
Cover photo: Unsplash